
DNA evidence does not prove guilt, especially in complex mixture cases. What is often presented in court as objective science is, in reality, a layered process built on assumptions, statistical modeling, software settings, and human decision-making.
DNA mixture interpretation is not a direct measurement. It is a scientific opinion generated from data, assumptions, and software modeling. In court, that distinction matters. Juries are often left with the impression that DNA software “identified” a person, when the real question is much narrower and much more conditional.
As a Minnesota criminal defense attorney who routinely litigates forensic DNA issues, Virginia “Ginny” Barron focuses on the gap between what the science actually shows and how it is presented in court. That gap can be critical in cases involving mixed samples, low-template DNA, and software such as STRmix. For related forensic issues, see this guide on touch DNA and low-template DNA in criminal cases and this article on probabilistic genotyping software in criminal cases. Barron Law Office also has a dedicated guide covering 10 questions to ask your attorney if DNA evidence is being used in your case.
What Is STRmix?
STRmix is probabilistic genotyping software used by forensic laboratories to interpret complex DNA mixtures, meaning samples that may contain genetic material from two or more individuals. Unlike older forms of DNA analysis that focus on cleaner, single-source samples, STRmix is designed to evaluate messy or ambiguous profiles using statistical modeling.
That does not mean STRmix identifies a person. It does not. STRmix evaluates how strongly the DNA evidence supports one hypothesis over another. In practical terms, that means the software is not answering, “Did this person leave the DNA?” It is answering a narrower question: “How much more consistent is this evidence with one scenario than another?”
That distinction is essential in court. Prosecutors and analysts may present the output in a way that sounds like identification, but the software is not making that kind of direct finding.
How STRmix Works in Practice
At a basic level, STRmix analyzes raw DNA data from an electropherogram and evaluates many possible contributor combinations. It compares competing hypotheses, often something like:
- the prosecution hypothesis, where the defendant is included as a contributor
- the defense hypothesis, where the defendant is not included as a contributor
The software then produces a statistical output known as a likelihood ratio.
This is one reason STRmix evidence should be handled carefully in court. Jurors may hear that the result is “computer generated” and assume it is purely objective. But STRmix depends on assumptions, analyst inputs, thresholds, and modeling choices. In that sense, the number is not simply discovered. It is generated through a process.
What Is Probabilistic Genotyping?
Probabilistic genotyping refers to a category of software systems, including STRmix, that use statistical models to interpret DNA mixtures. Traditional mixture interpretation relied more heavily on visible human interpretation. Probabilistic genotyping shifts more of that judgment into the software model, but it does not eliminate subjectivity.
Instead, it relocates it. Human decision-making still exists in areas like:
- the assumed number of contributors
- dropout assumptions
- stutter treatment
- analytical thresholds
- degradation settings
- population database choices
That is why probabilistic genotyping should not be mistaken for a machine-driven statement of truth. It is still an interpretive process. For a related explanation already published on the site, see What Is Probabilistic Genotyping Software in Criminal Cases?
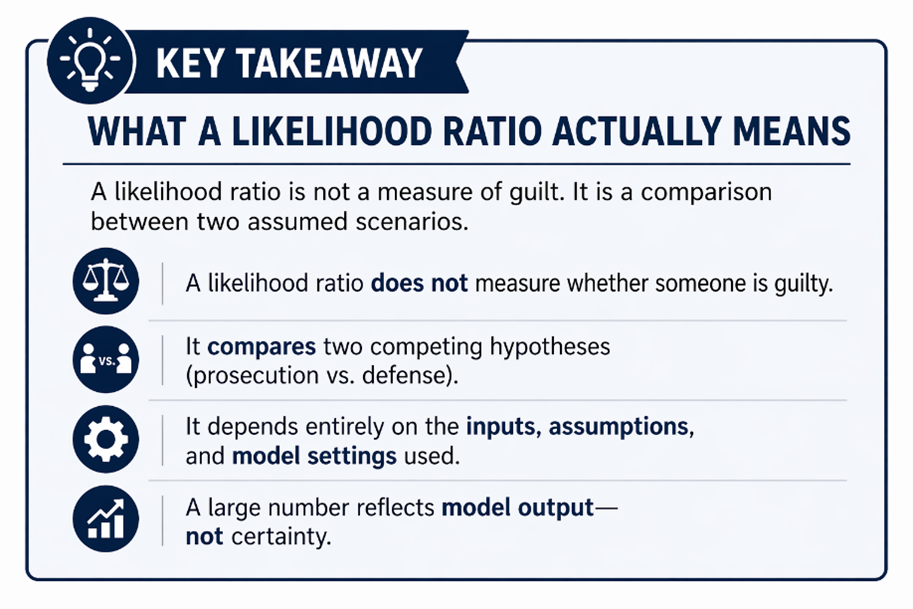
What a DNA Likelihood Ratio Actually Means
The central output of STRmix is the likelihood ratio, often abbreviated as LR. A likelihood ratio does not tell the jury whether someone is guilty. It does not tell the jury that the DNA came from the defendant. It compares how much better one hypothesis fits the observed data than another.
In plain terms, the question is:
How much more likely is the DNA evidence if the prosecution’s hypothesis is true than if the defense hypothesis is true?
That is a conditional comparison. It is not a statement that either hypothesis is actually true.
- LR greater than 1: the evidence supports the prosecution hypothesis more than the defense hypothesis
- LR less than 1: the evidence supports the defense hypothesis more than the prosecution hypothesis
- LR equal to 1: the evidence is neutral between the two scenarios
This is where DNA evidence is often overstated. A very large number may sound powerful, but it still does not convert into “the defendant is guilty” or “the defendant is the source.” It only measures relative support between competing assumptions.
Likelihood Ratios Explained Simply
One practical way to explain a likelihood ratio is to think about two competing explanations for the same event. Suppose you hear a repetitive sound outside your house. One explanation is that it is raining. Another is that someone turned on a sprinkler. If the sound is much more consistent with rainfall than a sprinkler, you may lean toward rain, but that does not prove it.
That is what a likelihood ratio does. It points toward the explanation that better fits the data. It does not establish truth with certainty.
This matters because jurors often hear enormous numbers attached to DNA testimony and understandably assume certainty. But those numbers are not direct measures of guilt. They are model-based comparisons.

Assumptions That Can Change the Result
Every STRmix result depends on assumptions, and some of the most important assumptions are rarely explained clearly to jurors.
1. Number of Contributors
Deciding how many people contributed to a mixture is one of the most consequential choices in the analysis. Changing the contributor count can materially change the result.
2. Allele Dropout
Dropout occurs when a real DNA signal is missing or too weak to be measured clearly. More assumed dropout can make it easier to include someone. Less assumed dropout can lead to a stricter interpretation.
3. Stutter Modeling
Artifacts such as stutter peaks must be handled statistically. Small differences in how those artifacts are treated can affect the final likelihood ratio.
4. Population Genetics Data
Likelihood ratios rely on population databases. Different databases can produce different statistical weights.
5. Software Parameters
Thresholds, degradation models, and peak-height expectations all matter. A result may look mathematically impressive while still being highly dependent on modeling choices made before the software produced its final number.
This is why defense review is so important. STRmix conclusions do not emerge in a vacuum. They come from a chain of decisions.
Where STRmix Can Be Challenged in Court
STRmix evidence is often presented as too technical for meaningful cross-examination. That is not true. There are multiple pressure points where the analysis can and should be tested.
Assumption Sensitivity
If a small change in contributor count, dropout assumptions, or modeling choices produces a significantly different result, that raises questions about robustness.
Validation Limits
Validation studies do not always reflect the real complexity of actual casework. A laboratory may validate software under controlled conditions that do not match the sample quality or contamination issues present in a specific case.
Analyst Input
Even with software, analysts make key decisions that affect the result. Those decisions can be questioned.
Overstatement in Testimony
In many cases, the biggest problem is not the software itself but how the result is described to the jury. A likelihood ratio can be framed in a way that sounds far more definitive than it really is.
For people facing charges involving forensic evidence, it can also be useful to review Barron Law Office’s broader discussion of what questions to ask when DNA evidence is being used in your case.
Minnesota-Specific Issues: Frye-Mack and Rule 702
In Minnesota, forensic evidence does not become immune from challenge simply because the underlying method has been used before. Courts still look at admissibility and reliability through frameworks that include Rule 702 and, where applicable, Frye-Mack principles.
A practical way to understand the distinction is this:
- Frye-Mack focuses on whether the scientific theory or technique is generally accepted
- Rule 702 focuses on whether the testimony is reliable and helpful in the actual case being tried
That difference matters in STRmix litigation. Even if probabilistic genotyping is generally accepted, the defense can still challenge whether the particular analysis in the specific case is foundationally reliable, whether the assumptions were valid, and whether the testimony is being presented in a misleading way.
Minnesota criminal defense cases involving forensic evidence often turn not on whether the software exists, but on whether the state can show that the way it was used in that case is reliable enough to help the jury rather than confuse it.
What Jurors Often Do Not Hear
Jurors are rarely told several critical things about DNA mixtures and software interpretation:
- different analysts can sometimes reach different conclusions from the same mixture
- changing assumptions can change the result
- a likelihood ratio is not a probability of guilt
- DNA mixture interpretation is conditional, not definitive
- the analyst and the software are answering a selected question, not every question the jury may think is being answered
That missing context is often where the defense has the greatest opportunity to expose weakness in the state’s presentation.
Strategic Defense Takeaways in DNA Mixture Cases
- STRmix does not identify a person; it compares competing hypotheses
- likelihood ratios compare scenarios, not guilt
- assumptions drive results
- software does not eliminate interpretation
- case-specific reliability matters as much as general acceptance
- cross-examination can reveal meaningful uncertainty
Why This Matters for a Criminal Defense Case
DNA evidence can be powerful, but powerful evidence can still mislead when it is overstated or presented without the right context. In complex DNA mixture cases, the key issue is not whether the software sounds advanced. The key issue is whether the result is reliable as applied in the actual case.
That is why forensic DNA litigation requires more than simply reading the lab report. It requires understanding the science, the assumptions, the legal standards, and how to challenge the state’s framing of the evidence.
To learn more about attorney Virginia “Ginny” Barron’s forensic background, visit the Attorney Profile page. If you are dealing with charges involving DNA evidence, you can also contact Barron Law Office to discuss the case.
Frequently Asked Questions About STRmix and DNA Mixture Interpretation
What is STRmix in simple terms?
STRmix is software that uses statistical modeling to evaluate whether a person could be part of a DNA mixture.
Does STRmix prove someone is guilty?
No. It compares how well competing scenarios fit the DNA evidence. It does not prove guilt.
What is a likelihood ratio?
A likelihood ratio compares how much more likely the evidence is under one hypothesis than another.
Can a likelihood ratio be misleading?
Yes. It can be misunderstood or presented in a way that sounds like a probability of guilt, which it is not.
Can two experts interpret the same mixture differently?
Yes. Different assumptions and analyst choices can affect the outcome.
Is STRmix accepted in Minnesota courts?
It may be used, but that does not end the inquiry. Case-specific reliability and the way the testimony is applied still matter in Minnesota criminal cases.